Reflection, for which functionality was already in place a few days ago, is now working. Here are a few test images. Enabling reflection on all the walls has caused a considerable performance hit. Renders are now around 3 times slower.
 Reflective Walls (Max Bounces: 30). Render time: 3.9 seconds
Reflective Walls (Max Bounces: 30). Render time: 3.9 secondsWhen I say max bounces are 30, it does not mean that all rays bounce 30 times. Most rays don't even make it past 7 or 8 bounces. The reflection coefficient in these images is 0.8 for the walls, and the refraction coefficient for spheres is also 0.8. Rays are traced only while the ray intensity (which starts off as 1.0) is atleast 0.01. Each bounce reduces this 'intensity' value, thereby limiting the number of bounces. So, 30 is just a 'very big number'.
 Reflective Walls (Max Bounces: 5). Render Time: 3.16 seconds
Reflective Walls (Max Bounces: 5). Render Time: 3.16 secondsHere we see a limited bounce result. With only 5 bounces, the reflections of the spheres lack detail. But we save some time this way.
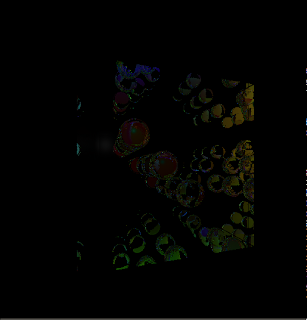 Diff of 5 and 30 bounce images
Diff of 5 and 30 bounce imagesClearly, there is a considerable difference between the two images, but the better image also takes around 20-25% longer to render.
 Reduced wall reflection coefficient to 0.4
Reduced wall reflection coefficient to 0.4Here is a more aesthetically pleasing version of the image, with reflection coefficient reduced to 0.4. The diffuse coloring of the walls is more pronounced than the reflections.
Finally, I rendered a high resolution version of the image (4096x4096) and downsampled it (1024x1024) to achieve an anti-aliased image of considerable quality. It took an eternity to render (229 seconds), but looks much better than the 512x512 version.

One small note about the images: You can notice black lines running along the corners of the cornell room. This is because of a 'minimum distance between bounces' threshold that has been set in the code. This prevents rays from bouncing twice off the same surface. Sadly it also has these side effects...
Another issue pending is stochastic reflection and refraction. Currently the system does not support surfaces that both reflect and refract, because rays never spawn off multiple secondary rays. To get this to work, the tracing engine has to trace multiple rays through each pixel. Some of these rays should reflect, and some should refract, depending on the coefficients of reflection and refraction. Monte Carlo integration may help out in blending these results together nicely.
Next on the agenda is splat blending. The refraction results look extremely noisy, and will hopefully benefit from some blending. Also to do is supersampling support, after which we will want adaptive supersampling.

























