Those of you who have used CUDA textures should be familiar with the insane programming interface that they present. Texture references can be declared only as global variables, and only in the file where you are using them. You can't pass them around as by-value/by-reference arguments in functions, you can't create them inside function/class scope, and you cannot make arrays of them.
This brings us to an interesting point. The way Multi-GPU programming is handled in CUDA is that you spawn off many CPU threads. Each CPU thread initializes its own GPU. For each thread, you create thread-specific variables that store pointers to the device memory, and allocate device memory in EACH thread. That's right, since memory is not shared between GPUs, if you are doing the same thing on many GPUs, you need to allocate the same stuff again and again, once on each GPU (of course, if you are doing Different things on different GPUs, thats a different ball game).
Now comes the fun part. Since you cannot create arrays of Texture References, and you cannot encapsulate them inside a class/structure, how on earth can you create one Texture Reference for each GPU? Should we hard code this? Should we replicate our code for each GPU we have, and just change the name of the Texture Reference to some unique name? The answer is NO!!
Well, it turns out that nVidia has sneakily done something here. When we spawn off multiple CPU threads, and select a different GPU in each thread, CUDA "automagically" creates a separate copy of the texture reference for each GPU. So, all you have to do is bind the SAME Texture reference again and again, once in each CPU thread (ie: once for each GPU). While it may look weird, because it looks like we are initializing the same(?) global variable several times, this actually works.
I have uploaded a small code sample here, that demonstrates this stuff. It loads a bunch of numbers onto the GPUs and squares them. This code sample uses some helper classes that I wrote to simplify CUDA development. This is still ongoing work, and may not be as good as a framework/library should be. Also, you will need Boost C++ libraries (the cpu threading and synchronization uses boost).
Sunday, January 3, 2010
Saturday, January 2, 2010
And we are back...
It has been far too long since my last post here. I guess regular blogging and regular exercise are equally hard :)
But I have not gone into torpor for the last few months. We ported our raytracer to CUDA this October, and development on that is still going on. Visit my website for the updates on that.
What still remains is a lot of code cleanup, optimizations and a few more features to add. Without wasting too much space, here is a brief overview of everything:
Raytracing with reflection, refraction, phong shading and shadows.
Scenes are point models (points are represented as oriented disks/splats).
An Octree is constructed on the CPU and uploaded as a linear texture onto the GPU.
Each GPU thread handles a single eye ray (along with all the bounces and shadow rays)
Performance:
On scenes of about 1-4 million points, we have a preprocessing time of around 1-2 minutes.
Raytracing at 512x512 for only primary rays + phong shading ~ 100-150 fps
Raytracing at 512x512 for average 5 bounces with shadows from one light source ~ 20 fps
Raytracing at 1024x1024 with 4 shadowcasting light sources and avg 3 bounces ~ 3-4 fps
All numbers are reported for a GTX 275.
But I have not gone into torpor for the last few months. We ported our raytracer to CUDA this October, and development on that is still going on. Visit my website for the updates on that.
What still remains is a lot of code cleanup, optimizations and a few more features to add. Without wasting too much space, here is a brief overview of everything:
Raytracing with reflection, refraction, phong shading and shadows.
Scenes are point models (points are represented as oriented disks/splats).
An Octree is constructed on the CPU and uploaded as a linear texture onto the GPU.
Each GPU thread handles a single eye ray (along with all the bounces and shadow rays)
Performance:
On scenes of about 1-4 million points, we have a preprocessing time of around 1-2 minutes.
Raytracing at 512x512 for only primary rays + phong shading ~ 100-150 fps
Raytracing at 512x512 for average 5 bounces with shadows from one light source ~ 20 fps
Raytracing at 1024x1024 with 4 shadowcasting light sources and avg 3 bounces ~ 3-4 fps
All numbers are reported for a GTX 275.
Saturday, August 29, 2009
A dash of OpenMP goodness
I work on a dual-core dual-socket 1.8 Ghz Opteron at the lab, and was wondering how much performance gain I would get out of a simple OpenMP 'parallel for' invocation...
Turns out that by simply adding this one line, above one of the for loops that controls ray generation, things can get pretty fast:
#pragma omp parallel for num_threads(8)
I have 4 cores, and I did tests with no threading, 4 threads and 8 threads.
Here are the CPU occupancy charts from system monitor:

Single Thread

Four Threads

Eight Threads
Performance:
1 Thread : 78 seconds/frame
4 Threads: 35 seconds/frame
8 Threads: 21 seconds/frame
Of course, the "clock()" function completely messes up in multi-threaded applications, and shows the same time (78 seconds) no matter what the actual time taken is. I measured these off a wall clock.
There seems to be some contention, due to which the resultant images for single threaded render and multi-threaded renders are different (by a very very small margin). The diff image has to be enhanced massively to see this. 4 pixels are off by 25%. Many pixels have a difference of 1 color value (out of 255). The images are otherwise undistinguishable to the eye. Need to fix this issue, but I will be taking a break from this project for a while, so updates may come after around 20 days.

Single Threaded Render

8 Thread Render
25 x Diff image
Turns out that by simply adding this one line, above one of the for loops that controls ray generation, things can get pretty fast:
#pragma omp parallel for num_threads(8)
I have 4 cores, and I did tests with no threading, 4 threads and 8 threads.
Here are the CPU occupancy charts from system monitor:



Performance:
1 Thread : 78 seconds/frame
4 Threads: 35 seconds/frame
8 Threads: 21 seconds/frame
Of course, the "clock()" function completely messes up in multi-threaded applications, and shows the same time (78 seconds) no matter what the actual time taken is. I measured these off a wall clock.
There seems to be some contention, due to which the resultant images for single threaded render and multi-threaded renders are different (by a very very small margin). The diff image has to be enhanced massively to see this. 4 pixels are off by 25%. Many pixels have a difference of 1 color value (out of 255). The images are otherwise undistinguishable to the eye. Need to fix this issue, but I will be taking a break from this project for a while, so updates may come after around 20 days.



Monday, August 24, 2009
Ray-bounce improvements and supersampling
2 small updates are in order.
First, the easy one: Anti-aliasing. I have been rendering larger images and downscaling them for achieving antialiasing, but now I added long pending support for multiple random rays per pixel. This way, I can achieve arbitrary sampling rates like 5 rays per pixel, rather than relying on rendering larger and larger images.

No super sampling (3.2 seconds)

8x super sampling (23 seconds)
Of course, nothing nice here, because the running time increases linearly with the number of samples. But here is a theory that I have: on GPUs, larger number of rays per pixel will gather smaller and smaller overhead. Why? Because of ray coherence. Since all these rays travel the same path (mostly), the amount of warp divergence will be very low. In a 2x2 pixel scenario, if we do 8x supersampling for each pixel, the entire warp (8x4 threads) will be well behaved, mostly.
Anyway, now coming to the slightly more obscure improvement. This has to do with an algorithm that I developed for 'seamless' raytracing of point models. Earlier, we had conditions like "if new collision point is within 0.1 units of old collision point of the ray, then ignore this collision point". This is needed because splat based models are not consistent. There can be multiple overlapping splats in the scene, and often, a ray reflected or refracted from one splat, will hit the immediate next splat. This should not happen because its like the ray hitting the same surface twice. Since we are not doing sub-surface scattering :P, we would not like this to happen. But such a naive condition also causes problems with legitimate collisions. For example, we see artifacts at wall corners, and at interfaces of objects where we would expect legitimate ray-hits, but the condition prevents a ray-hit from happening
So, the alternative idea is as follows: Assume the entire scene is made of closed objects. ie: there are no loose hanging objects whose back faces we can see from outside. We add a boolean parameter to each ray, stating which face of an object it would like to hit next (front face or back face). On reflection, this parameter remains same. On refraction, it flips (True to false, false to true). Initially, all primary rays want to hit front faces of objects. Back facing collisions are ignored. Similarly, after the first refraction, objects would like to hit the back face of a splat. This way, we can prevent same-surface collisions. Here is an image illustrating the virtues of this method:

Without Seamless raytracing

With Seamless raytracing
First, the easy one: Anti-aliasing. I have been rendering larger images and downscaling them for achieving antialiasing, but now I added long pending support for multiple random rays per pixel. This way, I can achieve arbitrary sampling rates like 5 rays per pixel, rather than relying on rendering larger and larger images.


Of course, nothing nice here, because the running time increases linearly with the number of samples. But here is a theory that I have: on GPUs, larger number of rays per pixel will gather smaller and smaller overhead. Why? Because of ray coherence. Since all these rays travel the same path (mostly), the amount of warp divergence will be very low. In a 2x2 pixel scenario, if we do 8x supersampling for each pixel, the entire warp (8x4 threads) will be well behaved, mostly.
Anyway, now coming to the slightly more obscure improvement. This has to do with an algorithm that I developed for 'seamless' raytracing of point models. Earlier, we had conditions like "if new collision point is within 0.1 units of old collision point of the ray, then ignore this collision point". This is needed because splat based models are not consistent. There can be multiple overlapping splats in the scene, and often, a ray reflected or refracted from one splat, will hit the immediate next splat. This should not happen because its like the ray hitting the same surface twice. Since we are not doing sub-surface scattering :P, we would not like this to happen. But such a naive condition also causes problems with legitimate collisions. For example, we see artifacts at wall corners, and at interfaces of objects where we would expect legitimate ray-hits, but the condition prevents a ray-hit from happening
So, the alternative idea is as follows: Assume the entire scene is made of closed objects. ie: there are no loose hanging objects whose back faces we can see from outside. We add a boolean parameter to each ray, stating which face of an object it would like to hit next (front face or back face). On reflection, this parameter remains same. On refraction, it flips (True to false, false to true). Initially, all primary rays want to hit front faces of objects. Back facing collisions are ignored. Similarly, after the first refraction, objects would like to hit the back face of a splat. This way, we can prevent same-surface collisions. Here is an image illustrating the virtues of this method:


Tuesday, August 18, 2009
Eigen2 Debug mode
Eigen's main page claims "Disabling asserts, by defining -DNDEBUG or -DEIGEN_NO_DEBUG, improves performance in some cases."
What they mean is that we need to call g++ with the -DEIGEN_NO_DEBUG option.
In this post, we test the effect of disabling asserts on a few test scenes. The first scene is a 512x512 render of a refractive sphere with reflective cornell room walls. The second scene is the same room, but 9 refractive spheres. The third scene is obtained by rendering the second scene at 1024x1024 with shadow rays. All scenes have 2 light sources.
Average running times with default settings (eigen in debug mode), were 3.6 seconds for the first scene, 4.3 seconds for the 2nd scene and 47 seconds for the third scene.
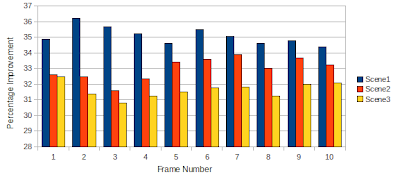
This reduces code run times pretty drastically (2.4, 2.8 and 33 seconds approximately for the three scenes described above). There is a clear 30% and above performance improvement when debug mode is disabled. Anyway, debugging with eigen is a nightmare (way too much boilerplate to sift through), and I use my own Vector library while doing serious debugging.
What they mean is that we need to call g++ with the -DEIGEN_NO_DEBUG option.
In this post, we test the effect of disabling asserts on a few test scenes. The first scene is a 512x512 render of a refractive sphere with reflective cornell room walls. The second scene is the same room, but 9 refractive spheres. The third scene is obtained by rendering the second scene at 1024x1024 with shadow rays. All scenes have 2 light sources.
Average running times with default settings (eigen in debug mode), were 3.6 seconds for the first scene, 4.3 seconds for the 2nd scene and 47 seconds for the third scene.

This reduces code run times pretty drastically (2.4, 2.8 and 33 seconds approximately for the three scenes described above). There is a clear 30% and above performance improvement when debug mode is disabled. Anyway, debugging with eigen is a nightmare (way too much boilerplate to sift through), and I use my own Vector library while doing serious debugging.
Octree boundary artifacts
I have traced the small artifacts that were popping up in the renders, to issues caused by octree leaf borders. It turns out that an octree border cutting through a smooth surface causes a slice to appear on the surface. This can be seen in the images below. At level 10, there are several small octree nodes, and they cause a large number of slices to appear on the surface. At level 4, there are very few borders of octree nodes, and therefore, we see no artifacts in the render. A more serious side effect is that rays start 'leaking' through the surface at these border points, and cause holes to appear on the surface. In animations, these holes pop in and out in a very distracting manner.

10 level octree (1.2 seconds to render)

8 level octree (1.3 seconds to render)

6 level octree (5 seconds to render)

4 level octree (80 seconds to render)
I don't have a solution to this problem yet, but I am thinking along the lines of adding splats to multiple octree leaves, or checking multiple nearby octree leaves while shading (rather than a single octree leaf).




I don't have a solution to this problem yet, but I am thinking along the lines of adding splats to multiple octree leaves, or checking multiple nearby octree leaves while shading (rather than a single octree leaf).
Shadow Rays
Added a visibility function that works between any 2 points in space (inside or outside the octree).
This means that I can finally implement shadow rays. [Maybe even radiosity :) but that is for another day]
But for the time being, here are the results of shadowing:

Single Light source

2 Light sources
Shadow rays can be computationally heavy as I found out:
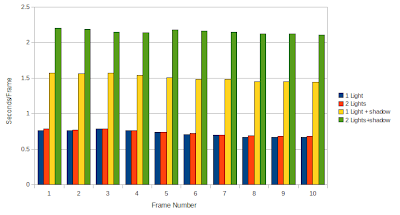
Not much time to spend today, so thats all for now.
This means that I can finally implement shadow rays. [Maybe even radiosity :) but that is for another day]
But for the time being, here are the results of shadowing:


Shadow rays can be computationally heavy as I found out:

Not much time to spend today, so thats all for now.
Subscribe to:
Posts (Atom)

